Figure 1: Scaling the quantities of unit tests for majority voting leads to improvements in performance across different policy models and reward models. Policy refers to the model that produces code solutions, while reward denotes the model that generates unit tests.
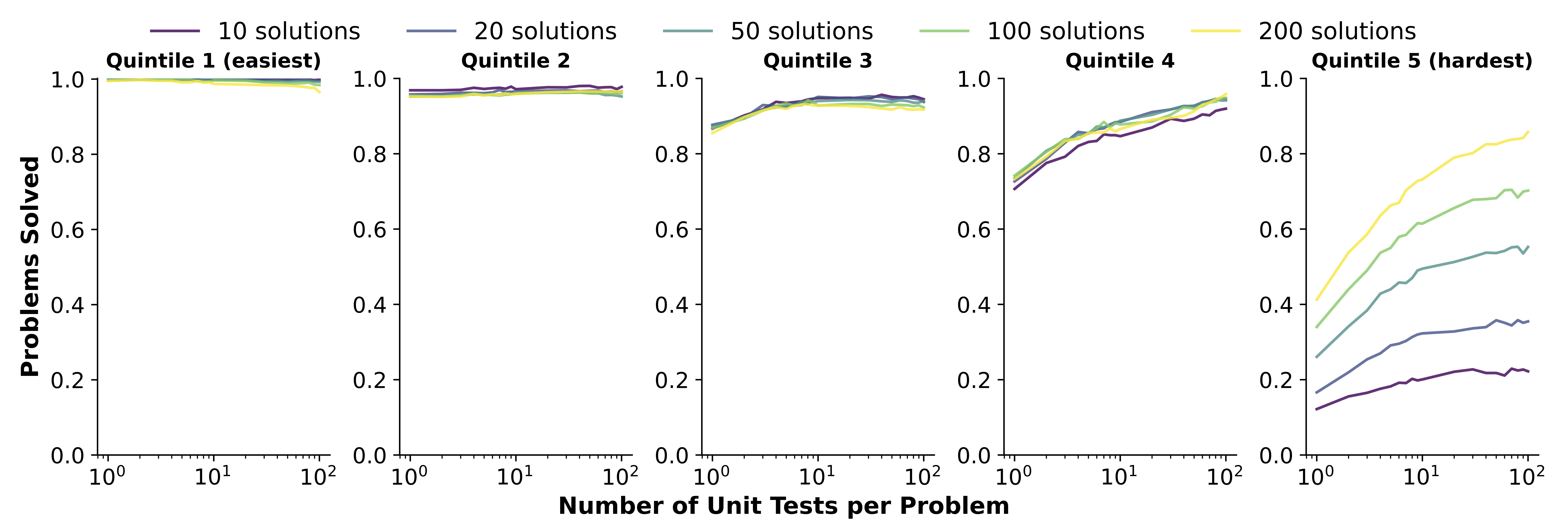
Figure 2: The improvements of best-of-N performance on problems of different difficulties, employing Llama3-8B as the policy model and GPT-4o as the reward model. Quintile 1 has the highest pass rate, while Quintile 2 has the lowest pass rate.
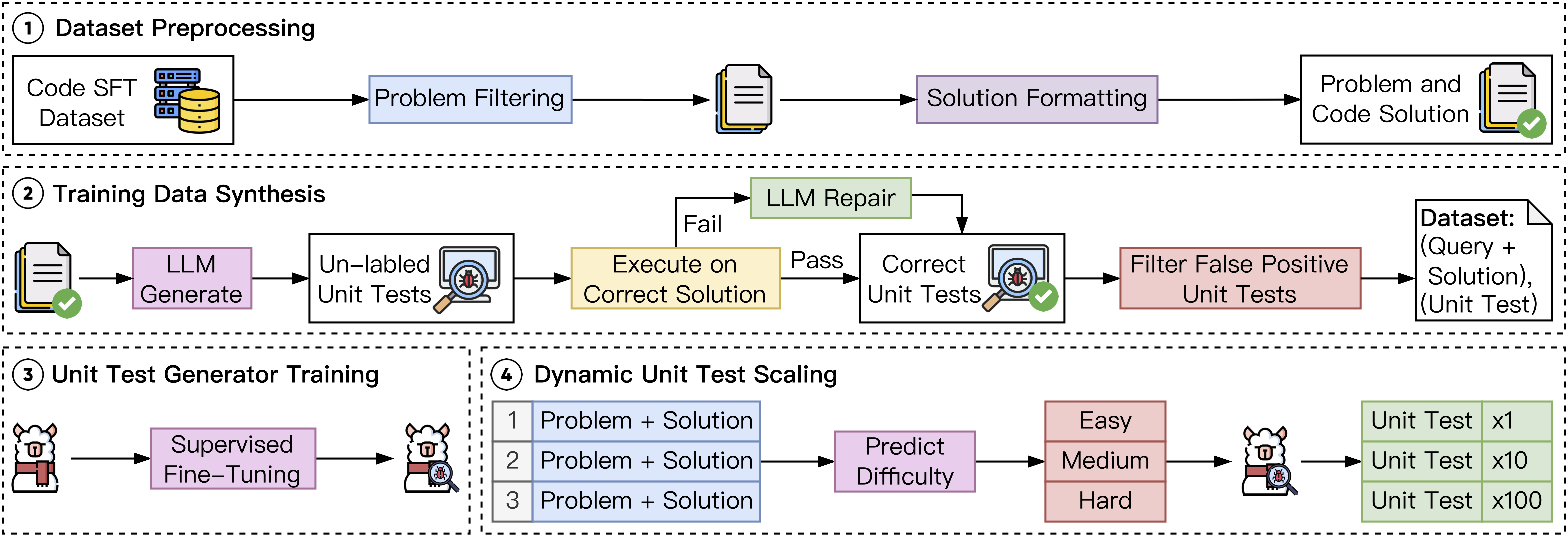
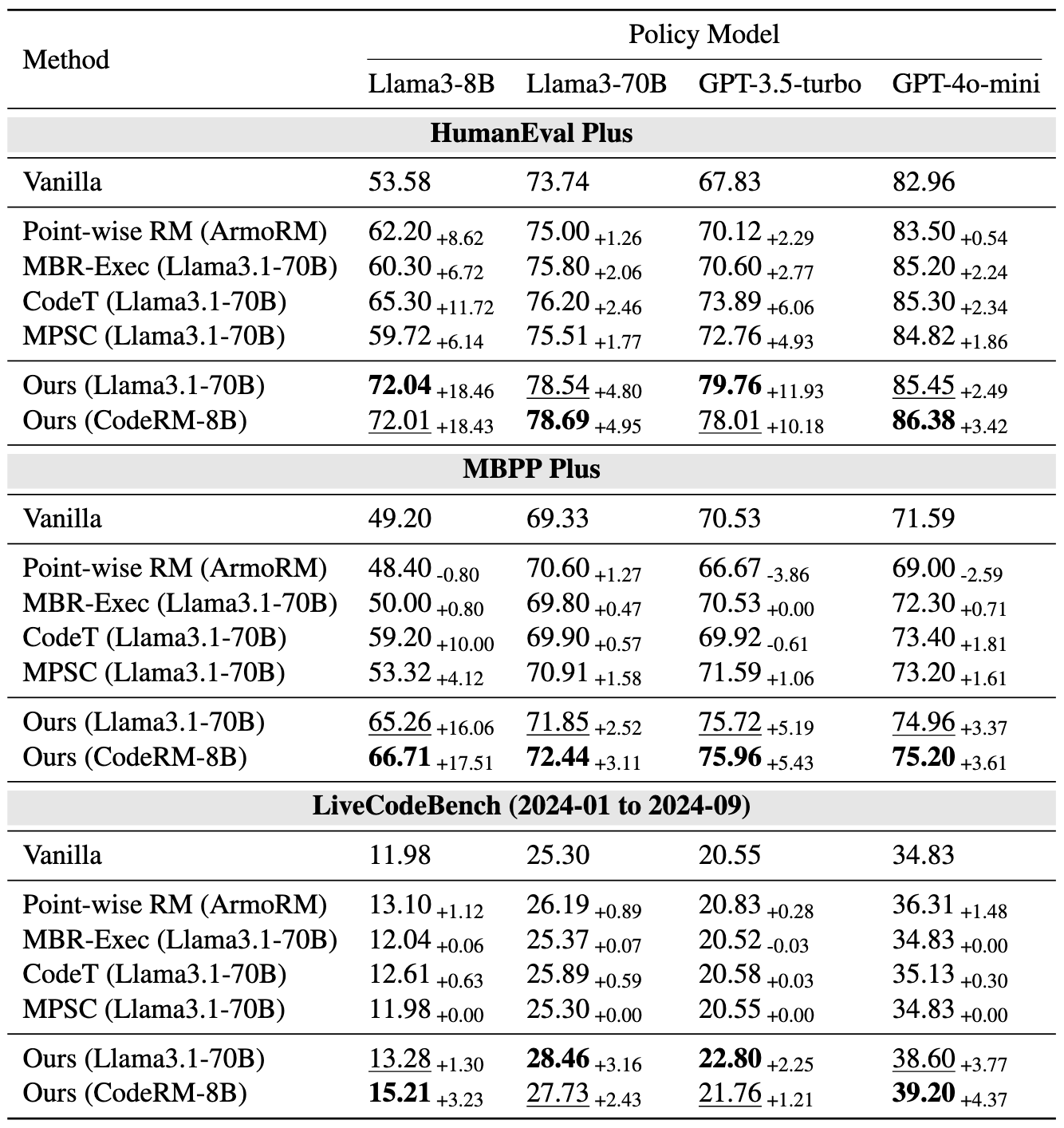
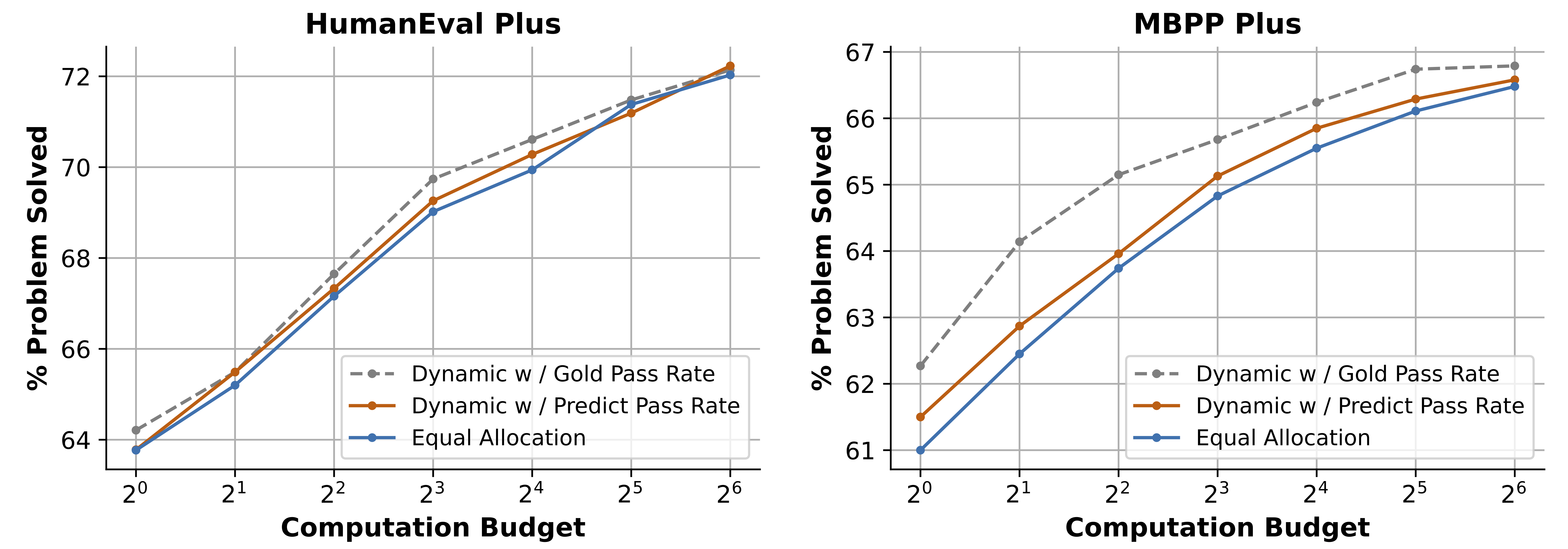
We explore the impact of scaling unit tests to enhance code reward signal quality across different LLMs and unit test scales. The result reveals a positive correlation between the number of unit tests and reward signal quality, with greater benefits observed in more challenging problems. In light of these observations, we train a unit test generator and employ dynmaic scaling over problem of different difficulties to facilitate efficient and high-quality unit test scaling.